

Everything begins with a refresher reading of my fundamental papers – yes, I use a set of papers and books as reference material. This paper is titled: “Why Events Are A Bad Idea (for high-concurrency servers)“, by Rob von Behren at the time of writing a PhD fellow at Berkeley [18]. Von Behren opens with: “Event-based programming has been highly touted in recent years as the best way to write highly concurrent applications. Having worked on several of these systems, we now believe this approach to be a mistake. Specifically, we believe that threads can achieve all of the strengths of events, including support for high concurrency, low overhead, and a simple concurrency model”, I’d say, at least, a fairly strong claim that he arguments in the paper with a set of interesting Benchmarks on reference implementations.
I wanted to put together a few concepts, and go through a systematic deductive reasoning, enriching my refresher reading list with few other interesting resources. What did I want to achieve? Well, nothing and all at the same time, not a real objective, but just a worth work to curious Engineers like me… Stay tuned!
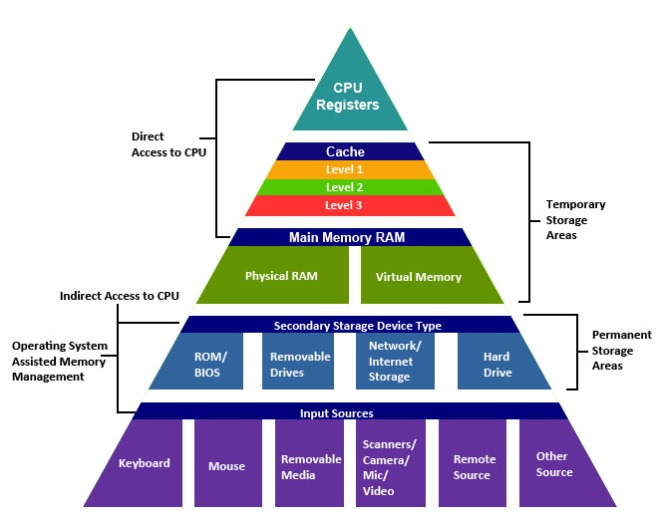
Memory Hierarchy
Access time increases descending the pyramid proposed in the below picture, as well as the storage capacity does [1]. Normally the access speed in such a layered hierarchy is measured in CPU (Central Processing Unit) cycles, and from top to down the number of cycles increases almost exponentially. For instance, roughly, to get access to an on-chip register/cache about 3=3*10^0 cycles are enough, instead, to get access to network/storage resources 2M=2*10^6 cycles are needed; getting into the main memory requires about 200=2*10^2 cycles. All this to say: I/O is expensive and needs to be managed carefully at design-time, according to the context and main use cases: as Engineers we know that does not exist a unique solution or design trick for all the problems in this world.
Thread Vs Process
A Process is an executable program/task for an OS (Operating System): physical resources, as well as memory, are allocated in separation to each Process operating concurrently. A Process can spawn many Threads that share the memory space, as well as the resources [2]. Threads can easily communicate each other using the parent Process shared memory: potentially, Threads can operate concurrently on contended resources into the parent’s shared area. On the other hand, Processes can communicate each other using OS’s Sockets, Pipes and Shared Memories (allocated on the purpose, specific area of mapped memory that can be shared among Processes). Each Process’ Thread has a dedicated Stack, but shares any open resource (e.g. file descriptors, sockets, etc.) with the parent Process, and so potentially with other Threads.
A Thread can be seen as a lightweight Process: as said memory and resources are shared with the parent Process, the only dedicated resource is the Stack. As intuitive, a Thread context switch is much lighter and quick than context switches between Processes (only a tiny Stack plus a few registers need to be saved).
What really is a Thread/Process? Exemplifying, a Thread and/or Process can be seen as a well defined set of machine codes/operations executable on a CPU, created by a compilation process and alternated by conditional jumps which are determined only at run-time. And, what really is a Context Switch? Again, exemplifying, a Context Switch can be seen as a well defined set of machine codes/operations executable on a CPU, aiming at saving the current execution context before to release the CPU (and its registries) to a new Process or Thread.
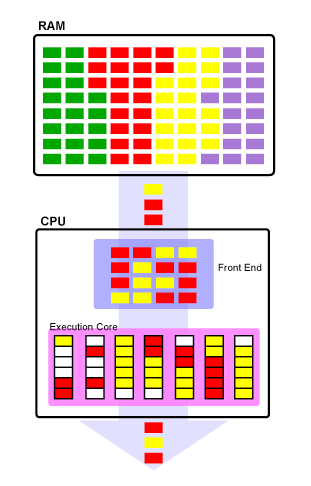
NOTE Hardware Thread is a different concept. Normally, multiplexing techniques allow at hardware level to improve the single core utilization creating different execution flows. Superscalar architectures are able to easily multiplex two separate and parallel execution paths onto a single core (the OS sees two separate cores) [6]. In the picture below and example of Hyper-Threading that improves the multi-tasking capability of a single physical core is provided: pipeline bubbles are reordered at Front End in order to increase as much as possible each core usage.
Non-Blocking Vs Blocking I/O
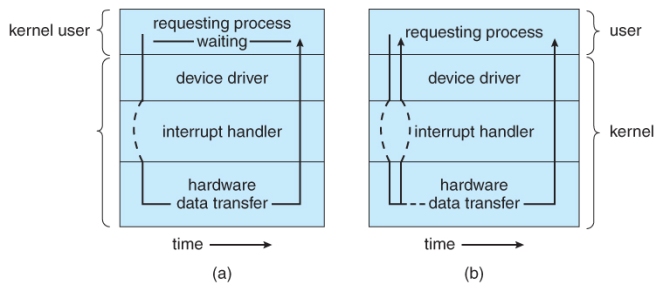
A Blocking I/O operation imposes a stop-the-world pause to the main Process/Thread: the caller waits until the operation is completed. On the other hand, a Non-Blocking I/O or Asynchronous I/O operation does not impose any stop-the-world pause to the main Process/Thread: the caller continues its execution, meanwhile in the background the I/O will be completed by the OS. As intuitive, in the second case, the caller has to either poll a buffer for checking the status, or register a callback to get notified asynchronously upon the completion [3].
Client code using Non-Blocking I/O is fairly complex, in terms of design and debugability: a-priori, no assumption can be done about the completion of I/O operation(s), code has to take this into consideration and has to be organized accordingly (events flow out from the channels with non-determinism, buffers are filled up and client code has to carefully deal with these aspects). As opposite, Blocking I/O is normally stream oriented: upon the I/O request, the best is done to serve immediately the request and return the data to the caller as the result of the System Call.
Non-blocking I/O is a scalable approach in several scenarios; but, let’s find immediately a case in which such statement is easily not verified. For instance, let’s consider the case of a single process dealing with a huge amount of events coming from many File Descriptors (FD). As clear, the benefits of Non-Blocking I/O immediately disappear in such a scenario: the process is supposed to deal with CPU-bound unit of works (the I/O-bound part is already accomplished, the network events are now in the buffers), serialized in the single software execution path on the underlying resources (i.e. Caches, Memory, etc.), meaning that the CPU has to execute each single event, one after another.
C10K Problem – From where Events Loop comes from
Around 1999s the problem of managing tens of thousands of active stream-oriented connections on a single server was analyzed, and the terms C10K (i.e. Connections 10K) was coined. The analyzed problem (even known as “Apache Problem”) considered a HTTP server operating on a single commodity box and serving tens of thousands of active connections (careful, not requests per seconds) using the Thread-per-Connection model. At that time, the reference architecture for the CPU was: single processing unit (aka single core) working in the range of frequencies [166, 300] MHz. Clearly, on such an architecture, in a high concurrent scenario, in terms of processing time the cost of multiple context switches is relevant: the throughput decreases as soon as the maximum number of manageable connections is reached. 10K active connections for commodity servers was an hard limit in the 1999, so to overcome such limitation reactive programming techniques were applied: Reactor Design Pattern [7] allowed to develop single process and single threaded servers dealing with I/O by using an event loop. This solution allowed to overcome the hard limit for many reasons. Firstly, OSes like Linux did not have real OS-level Thread (only with NTPL [16] Linux 2.6 got such abstraction). Secondly, on hardware architectures of that time, a Thread Context Switch was an heavyweight operation in terms of elapsed time (CPUs were slow, no hardware-support), strongly impacting the overall Scalability. Finally, again, hardware architectures of that time were not multi core and Hyper-threaded.
Pills of Non-Blocking I/O: select()/poll()/epoll()
Such System Calls work with FDs which abstract resources like Files and Sockets. According to the POSIX specification [20], each FD can be associated to one inode [21], and potentially one inode can be linked by multiple FDs. An inode is a data structure of the OS Kernel that abstracts the physical resources; in a very simplified version, it may be seen as a buffer – this is the simplification that I will use afterwards.
FDs’ events can be polled with different mechanisms and using different System Calls [10][11]. select() and poll() are equivalent System Calls to get access to the events generated by a set of FDs, actually poll() is a bit more modern and tackles some limitations of select(). epoll() is an evolution of poll(), available only on Linux (select() and poll() with different naming are available on almost all other OS platforms) that simplifies the task to fetch events from a set of FDs; more interesting, it solves a bunch of scalability issues of select() and poll(), the most known is the linear scan problem to detect the FDs getting new events.
As System Calls, select(), poll() and epoll() need a Light Context Switch: User- to Kernel-mode switch. The polling frequency is configured programmatically, but for epoll() it cannot go under the millisecond which is a limitation itself; in case of select() and poll() the polling frequency can be set to microseconds. Now, let’s imagine a real case scenario, with a select()/poll() on thousands of FDs and polling each few microsecond. The question is: is this a scalable approach? Other question, in such a case, what if only 1 of the thousands of FDs is updated each time? … Food for thoughts!
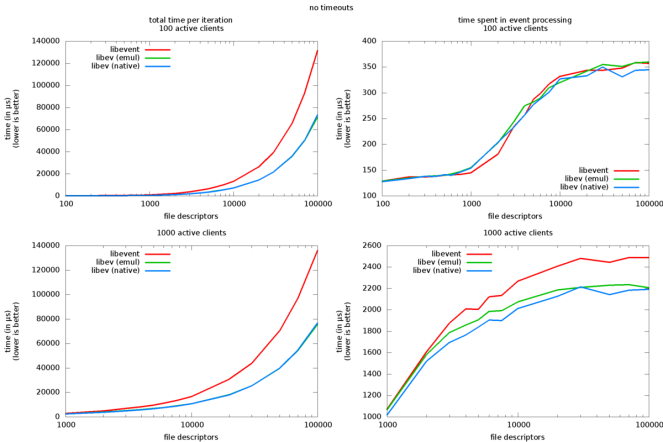
In [12] an interesting benchmark of application libraries based on epoll() is provided, namely libevent and libev. Below pictures report the outcome from the benchmark sessions. I would focus the attention of the time spent in processing the events: as soon as the number of FDs approach 1K, with a small number of active clients, on average 150 microseconds are spent to only deal with the events generated in the benchmark. Such overhead introduced by the event processing is a relevant amount of time that has to be taken into consideration in any real-case scenario.
Short- Vs Long-lived Connections
A distinction has to be made between Short- and Long-lived Connections. A Long-lived connection is normally an interactive session between a Client and a Server (in this category can fall the long data transfers normally executed per chunk); on the other hand, a Short-lived session is normally a 1-off connection established only to fetch some very small data – no needs of successive interactions.
Dealing with the I/O – A few Key Models
Preamble
From a practical perspective, I/O Waits and Context Switches cannot be avoided with the default Network Stacks and System Call APIs shipped with generally available versions of the OSes. Interesting point is: techniques like select()/poll()/epoll() block and wait as programmatically configured, and potentially pull one or many frames of data per System Call (i.e. one Context Switch is likely to retrieve Events from multiple FDs).
Single Threaded Non-Blocking I/O
Events are pulled from the buffer(s) and processed in sequence by the single execution unit, i.e. a Process and/or Thread. Therefore, even if the OS supports multicore Non-Blocking I/O, having a single Process/Thread processing the supposedly CPU-bound events is a performance killer: it turns out to be a basic serialization scheme.
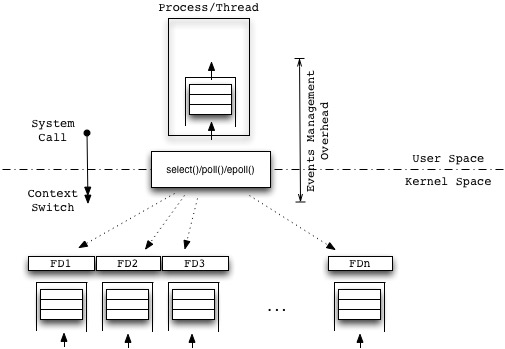
Algorithm
- Wait
- Make System Call to selector()/poll()
- Check if something to do (iterate linearly over FDs, optimized in epoll())
- If nothing to do, Goto (1)
- Loop through tasks
- If its an OP_ACCEPT, System Call to accept the connection, save the key
- If its an OP_READ, find the key, System Call to read the data
- If more tasks Goto (3)
- Goto (1)
Advantages
- Light Context Switches (User to Kernel mode).
Disadvantages
- Inefficient for Short-lived Connections (Events handling overhead and polling time can outweigh the current amount of work).
- Serial processing (from the Process/Thread perspective).
- Bottleneck (in the Event Loop).
- CPU-bound tasks executed serially kill the performances.
- Complex code.
- Complex debugging.
Multithreaded Non-Blocking
Events are pulled from the buffer(s) and dispatched on worker Threads: a Puller Thread dispatches events over a set of pre-allocated Worker Threads in a Thread Pool. Events processing is concurrent with this dispatching scheme, and can take benefit of native multi core processing of modern hardware architectures.
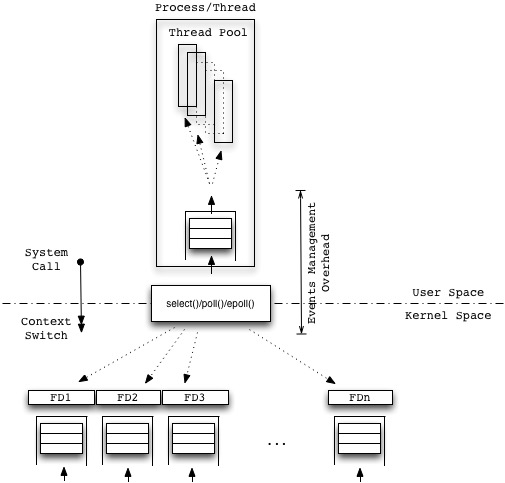
Algorithm
- Wait
- Make System Call to selector()/poll()
- Check if something to do (iterate linearly over FDs, optimized in epoll())
- If nothing to do, Goto (1)
- Loop through tasks and dispatch to Workers***
- If more tasks Goto (3)
- Goto (1)
*** For each Worker
- If its an OP_ACCEPT, System Call to accept the connection, save the key
- If its an OP_READ, find the key, System Call to read the data
Advantages
- Light Context Switches (User to Kernel mode).
- Higher Scalability and better Performances in processing CPU-bound tasks.
Disadvantages
- Bottleneck (in the Event Loop).
- Multi processing is driven by a dispatcher, so delayed in time (before to start processing new stuff, a Thread has to be weaken up after the Dispatcher has analyzed the event itself); a time consuming level of indirection.
- Complex Code.
- Complex Debugging.
Blocking Multithreaded
Each I/O request is served by a single Thread, that parses the request, blocks waiting for the operation to complete and finally processes the data retrieved by the I/O task. Threads work independently, they perform the System Calls and implement the overall computation taking advantage of native multi processing capabilities of modern hardware architectures.
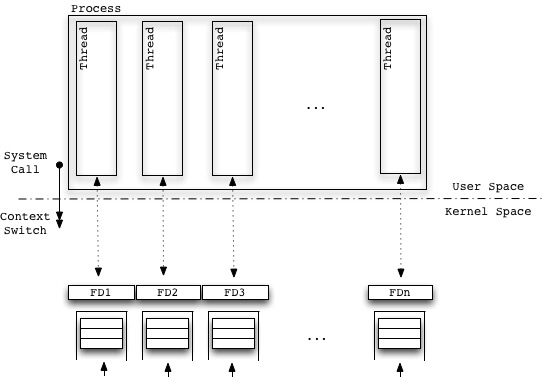
Algorithm
- Make System Call to Accept Connection (thread blocks there until we have one)
- Make System Call to Read Data (thread blocks there until it gets some)
- Goto (2)
Advantages
- No evident Bottleneck.
- Pure multi-processing (no level of indirection).
- Better Performances (no need to analyze events).
- Number of runnable Threads is potentially limited by the available Virtual Memory.
- The rule NumberOfCPUs * 2 + 1 is appropriate only in case of hard CPU-bound tasks, here we’re talking about mixed I/O-first and CPU-second tasks.
- Easier Code.
Disadvantages
- Higher number of Context Switches on average.
- Higher memory usage (as many Threads’ stacks as the number of FDs).
- Fairly complex Debugging.
Mailinator Case – Thousands of Threads and Blocking I/O
The question that raises in [5] is then: why should an application re-code what the Kernel is supposed to do? To say, managing concurrency on multiple cores by selecting events and dispatching them over workers at application level (Single Threaded Non-Blocking I/O is just a case study, no practical scalable application can be built on it). Another question, is the Kernel supposed to do that in Kernel-space, and underneath any other application? Paul Tyma, creator of Mailinator and former Google’s Architect, proves the point: modern hardware architectures are designed for concurrency, and modern OSes are optimized to work on modern hardware architectures. From the field experience, Multithreading and Blocking IO have many advantages, among them: superior performances, straightforward code, usage of native features of modern architectures, and trust in low level dispatching mechanisms (provided by the Kernel itself)
Disruptor Pattern – Massive Multithreading
Disruptor is a design pattern coming out from the financial industry, abd defining an inter-thread communication mechanism able to assure 22M of events processed per seconds on a single box [9]. Surprisingly, the reference implementation is written in Java and makes use of multithreading and mechanical sympathy in the design. It is a complex lock-free interaction scheme [15] that assures extremely high throughputs and so extremely low processing latencies.
Nginx Case – Workers Threads and Non-Blocking I/O
Nginx is a modern Web Server developed in early 2000s [22] and since then incessantly evolving into a trusted platform to host business critical services. Nginx is designed ground-up to use Asynchronous I/O and multi processing capabilities of modern hardware architectures: a single dispatcher Thread/Process pulls the Events and dispatch them over the Worker Threads/Processes. It outperforms Apache Web Server in many use cases as described in [23]. Of course, this does not mean that Nginx’s I/O model is more efficient than Apache’s one: Apache has been release in 1995, Nginx in 2004, so the code base of Nginx is supposedly optimized for modern architectures on which benchmarks run.
Final Thoughts
As for all engineering stuff, the best is always a trade-off, really! Seriously now, between Events and Threads of course the best approach is in between, as proven in this lightening paper of Matt Welsh [14] (creator of SEDA [19]): “A Design Framework for Highly Concurrent Systems”. Many factors come into play approaching the design of Scalable systems, examples are: type of Connections, type of Tasks, ability to split the Tasks into Sub-Tasks and so pipeline them, characterization of the Tasks (% CPU and IO processing), etc. All these factors have to be taken into consideration: a I/O handling technique is not superior to the other, but the superiority depends on the case or at least the most frequent use case(s).
Let’s try to narrow down a few thoughts from the concepts refreshed above. Here below there is a straightforward comparison.
Synchronous I/O: Single Thread per Connection.
- Blocking I/O
- High Concurrency (improved a lot with the advent of NPTL [16])
- As many Threads as I/O FDs
- Memory usage is reasonable high
- Make better use of multi-core machines
- Coding is much simpler, as well as debugging
Asynchronous I/O: Single Dispatcher Thread, many Worker Threads.
- Non-Blocking I/O
- Reduced level of Concurrency (Dispatcher is a bottleneck)
- Many Threads come into play to effectively manage the traffic
- Application handles Context Switching between Clients (Dispatcher Thread/Process): application context needs to be saved to work in an Event Loop (normally, Threads does this into their own stack, and this is managed at Kernel level)
- Memory usage is near optimal
- Coding is much harder, as well as debugging (two levels of Asynchrony: events pulled from the OS’s buffers, and pushed to Threads to process them)
At this point, a reasonable question might be? Is Asynchronous I/O really faster? Well, searching the web, there are no dedicated benchmarks to exhaustively answer the question, but some interesting discussion points out the opposite [17]: Blocking I/O with native Thread-per-Connection model is 25%/30% faster than epoll()-based solution, and epoll() that is the fastest and more advanced Asynchronous I/O System Call so far. Moreover, Paul Tyma proposes its results in [5]: on a Linux 2.6 Kernel, a reference implementation of Synchronous I/O Server outperforms the Asynchronous I/O one, apparently 100 MB/s Vs 75 MB/s of throughput on a single box.
Intuitively, if Threads operate on independent data (CPU-bound part of the computation), and no synchronization is needed (no further Context Switches, apart the ones described in the Algorithm above), the native High Concurrency and so Performances of pure Multithreading can make the difference.
References
[1] https://en.wikipedia.org/wiki/Memory_hierarchy
[2] https://msdn.microsoft.com/en-us/library/windows/desktop/ms684841(v=vs.85).aspx
[3] https://en.wikipedia.org/wiki/Asynchronous_I/O
[4] https://en.wikipedia.org/wiki/C10k_problem
[5] https://www.mailinator.com/tymaPaulMultithreaded.pdf
[6] https://en.wikipedia.org/wiki/Hyper-threading
[7] https://en.wikipedia.org/wiki/Reactor_pattern
[9] https://lmax-exchange.github.io/disruptor/
[10] https://daniel.haxx.se/docs/poll-vs-select.html
[11] http://www.ulduzsoft.com/2014/01/select-poll-epoll-practical-difference-for-system-architects/
[12] http://libev.schmorp.de/bench.html
[13] http://www.kegel.com/c10k.html
[14] http://www.eecs.harvard.edu/~mdw/papers/events.pdf
[15] http://lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf
[16] https://en.wikipedia.org/wiki/Native_POSIX_Thread_Library
[17] http://www.theserverside.com/discussions/thread.tss?thread_id=26700
[18] http://www.cs.berkeley.edu/~brewer/papers/threads-hotos-2003.pdf
[19] https://en.wikipedia.org/wiki/Staged_event-driven_architecture
[20] https://en.wikipedia.org/wiki/POSIX
[21] https://en.wikipedia.org/wiki/Inode
[22] https://en.wikipedia.org/wiki/Nginx
[23] http://wiki.dreamhost.com/Web_Server_Performance_Comparison

Actually, there is an in-memory database Redis which has core architecture similar to Single Threaded Non-Blocking I/O. The only advantage this gains is no locking. Locking is performance killer for this particular database is because it is completely in-memory and locking overhead cannot be disregarded
LikeLike
Very good point. I am a big fan of Redis. But, worth mentioning that Redis’ performance is also constrained by its intrinsic design decisions: not really scaling with the number of available CPUs.
LikeLike