Consequences of a “Bad Hire”
Among a set of apples, there is always one which is “bad”!
Among a set of apples, there is always one which is “bad”!
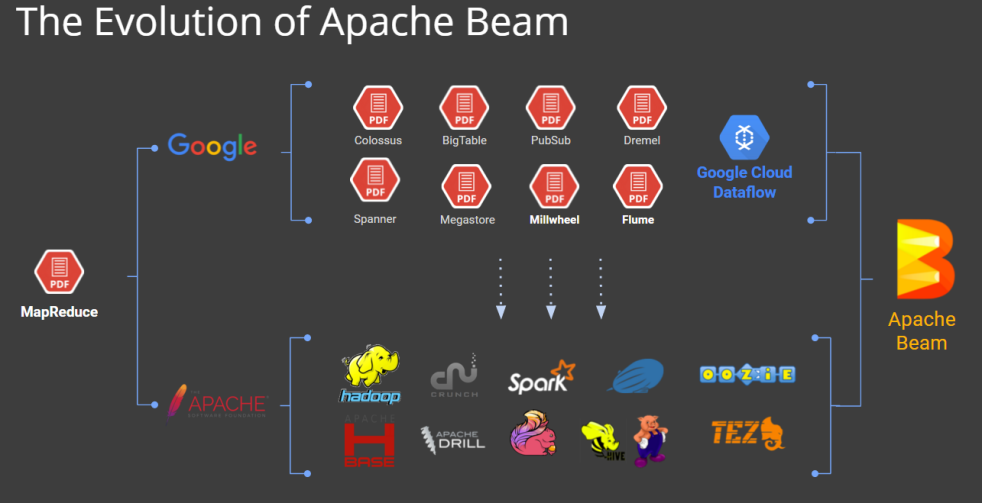
When it comes to stream processing, the Open Source community provides an entire ecosystem to tackle a set of generic problems. Among the emergent Apache projects, Beam is providing a clean programming model intended to be run on top of a runtime like Flink, Spark, Google Cloud DataFlow, etc. A really convenient declarative… Continue reading Apache Beam+Apache Flink/Spark for Batch&Stream Processing
Originally posted on Dan Tehranian's Blog:
(This post is part 1/2 in a series. For part 2 see: Managing Secrets with Ansible Vault – The Missing Guide (Part 2 of 2)) Background and Introduction to Ansible Vault Once you’ve started using Ansible to codify the configuration of your infrastructure, you will undoubtedly run into…
Originally posted on the morning paper:
HopFS: Scaling hierarchical file system metadata using NewSQL databases Niazi et al., FAST 2017 If you’re working with big data and Hadoop, this one paper could repay your investment in The Morning Paper many times over (ok, The Morning Paper is free – but you do pay with your…
Call for Papers! ADIDSE IARIA Special Track aims at tackling the problems and discussing the advancements in Data-Intensive Distributed Systems Engineering with the community of Engineers and Scientists out there. Come and join us… The advent of the IoT (Internet of Things), by forecasts, is going to bring 40 Billion connected devices by 2020. Such… Continue reading Advancements in Data-Intensive Distributed Systems Engineering
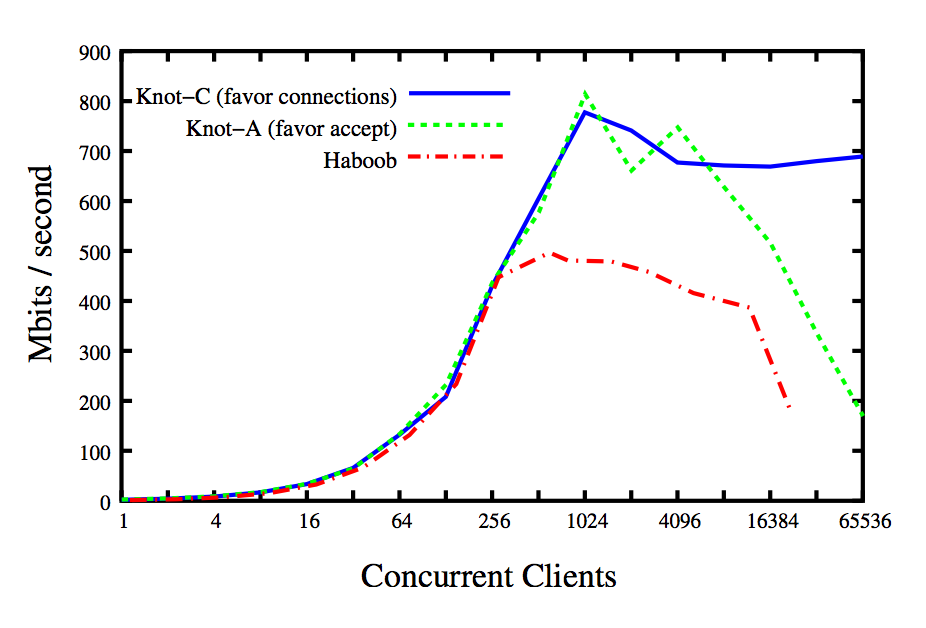
Knot is a network server as well as Haboob. The difference is the concurrency model: Knot is thread-based, instead Haboob is event-based [9]. Clearly, from the benchmark results, the poll()/epoll() mechanism is a serious bottleneck as soon as the number of active concurrent clients become relevant (in the specific case, at 16384 clients the trashing… Continue reading Scaling to Thousands of Threads
Engineers with leadership roles supposedly work with stakeholders to collect requirements and then lead the developments accordingly. Often, the set of stakeholders and requirements are not clearly defined and Engineers struggle to lead effectively the efforts in the right direction, within the expected timeframe. Such struggles, not rarely, bring to failures: how many times a… Continue reading Lessons learned from the field: listen your Stakeholders
Everything begins with a refresher reading of my fundamental papers – yes, I use a set of papers and books as reference material. This paper is titled: “Why Events Are A Bad Idea (for high-concurrency servers)“, by Rob von Behren at the time of writing a PhD fellow at Berkeley [18]. Von Behren opens with: “Event-based… Continue reading Scalable I/O: Events- Vs Multithreading-based
We are living the era of buzzwords, and Docker is for sure one of those in the technological landscape. Docker has a common sense definition: hypervisor-free virtualization. In other terms: running VMs without any hypervisor-based virtualization support. Now, how is this possible? What is the arcane trick to achieving that? Let’s live a short journey… Continue reading Dense Virtualization via Linux Containers
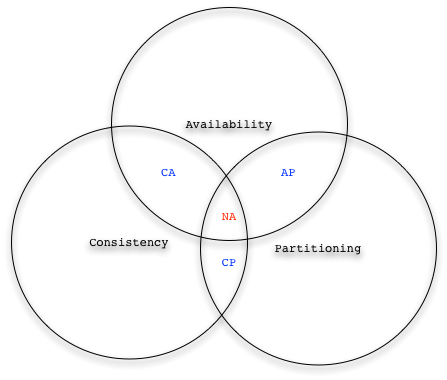
A question raises spontaneously: why Eventual Consistency? Isn’t ACID enough? Let’s try to understand the need for Eventual Consistency guarantees when we talk about Distributed Computing on large scale, and of course Data is involved. With the advent of Internet and Cloud services, Databases and more in general Data Storage technologies have undergone a radical change:… Continue reading Pills of Eventual Consistency