

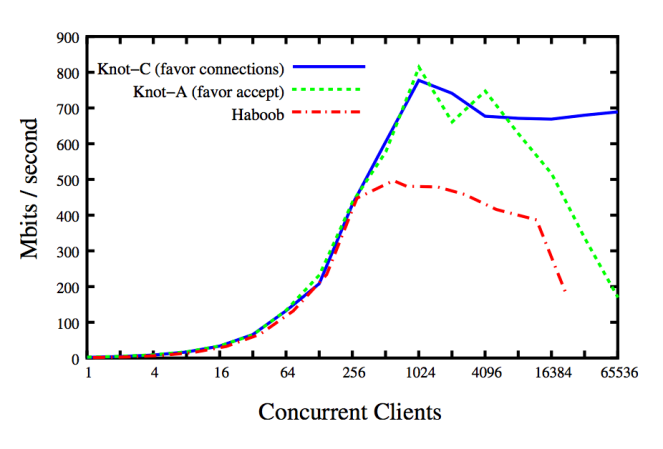
Knot is a network server as well as Haboob. The difference is the concurrency model: Knot is thread-based, instead Haboob is event-based [9]. Clearly, from the benchmark results, the poll()/epoll() mechanism is a serious bottleneck as soon as the number of active concurrent clients become relevant (in the specific case, at 16384 clients the trashing hits hardly and the benchmark cannot continue). For the sake of clarity, ‘favor connections’ and ‘favor accept’ are two different thread scheduling policies for the network server.
Eric Brewer is the Computer Scientist from Berkley University who came up with the famous CAP Theorem [15]. In a series of papers, he tries to demystify and fix the misconceptions around thread-based concurrency and its inherent scalability. In particular, in two seminal works “Why Events are a Bad Idea” [9] and “Scalable Threads for Internet Services” [8] he compares the performance of event- and thread-based scalable servers demonstrating that the thread model scales almost linearly with the Operating System (OS) capabilities: as soon as the OS gets backpressure from the hardware, trashing happens and the overall scalability gets affected. Interesting is another point: in 2003, such trashing was happening only when hundreds of thousands of threads were dealing with active network connections. Interesting, no?
Let’s go through a few resources from the literature with the aim to discuss the advantages of thread-based concurrency, especially on modern hardware architectures.
Pills of History
In these cases, a picture is worth a thousand words.
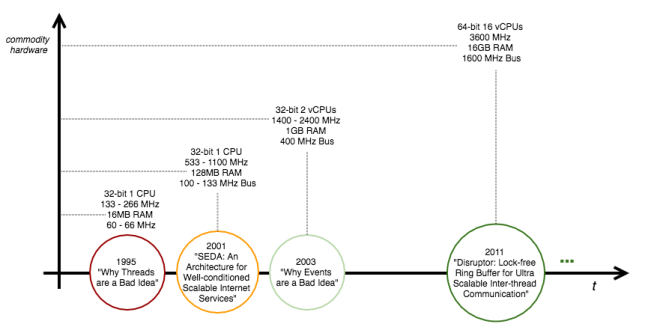
Hardware is looked up in [6] from the processors timeline. As a matter of fact, with the hardware improvements seen in these last years, the technological trend consisted in exploiting the hardware parallelism with massive multi-threading. Current efforts are in the field of lock- and wait-free non-blocking synchronization algorithms and data structures [7] for CPU-bound applications. Examples of lock-free ultra-scalable data structures are the LMAX Disruptor [16] (26 Million operations per second with mean latency of 52ns), and the Azul lock-free Hashtable [17] (between 30 and 50 Million operations per second).
A few Facts
A few numbers from a typical commodity machine to benchmark its default limits in terms of memory and threads. In particular, it is interesting to grasp per process the i. amount of allocable virtual memory and ii. stack size, per user the iii. maximum number of processes, and finally per system the iv. maximum number of threads.
# linux kernel version [hailpam@jarvis ~]$ uname -r 3.10.0-229.11.1.el7.x86_64 # allocable virtual memory [hailpam@jarvis ~]$ ulimit -v unlimited # stack size [hailpam@jarvis ~]$ ulimit -s 8192 # maximum number of processes per user [hailpam@jarvis ~]$ ulimit -u 4096 # maximum number of threads [hailpam@jarvis ~]$ cat /proc/sys/kernel/threads-max 255977
As a side note, the version 3.1 of the Linux Kernel was released late 2011. Looking at the figures, it seems that from a system, process and user perspectives on a modern Linux OS there is really no concern about the number of threads allocable to scale to thousands of active connections [8, 9], by taking benefit of multicore capabilities of the modern hardware architectures.
Anatomy of Events/Threads Dualism
When it comes to design scalable network servers for modern Internet Services, one question always raises up: is one thread per connection scalable enough, or should non-blocking IO be adopted?
Events- and thread-based models are dual [1], meaning that a program developed with one model can be directly mapped to a program of the other model; both models are logically equivalent even if they use different techniques and constructs; the performances of both models are practically identical since scheduling techniques are adopted for both of them.
The duality argument from Lauer and Needham (late 70s) brings up a few interesting points putting side by side Events and Threads.
| Events | Threads |
| Event handler | Monitor |
| Event loop | Scheduling |
| Event types accepted by event handler | Export functions |
| Dispatching a reply | Returning from a procedure |
| Dispatching a message, awaiting a reply | Executing a blocking procedure call |
| Awaiting messages variables | Waiting on condition |
According to the duality argument, both models yield to the same blocking points when equivalent logic is implemented. Said that, given comparable executing environments, the two models should be able to achieve the same performance.
IO Vs CPU Parallelism
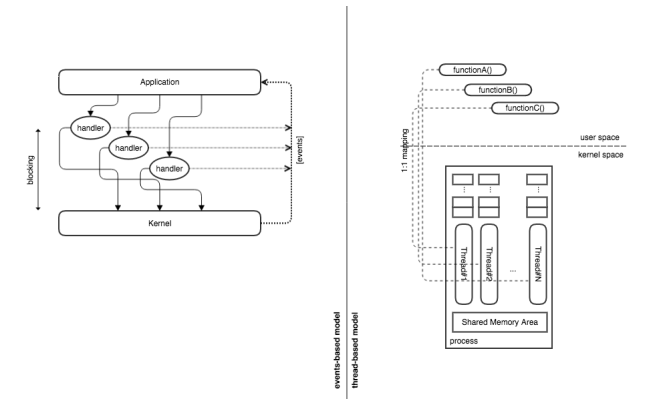
When it comes to IO operations, two fundamental models can be adopted: 1. blocking or 2. non-blocking.
The blocking model is based on the OS capability to allocate the CPU time to a different process/thread whenever an IO operation is performed: the IO process/thread is suspended, a new process/thread is activated, as soon as the IO is complete a signal is issued to wake up the suspended process/thread and put asleep the actual active one. On the other side, the non-blocking model is based on the Application capability to continuously poll in a loop the status of IO operations within a single process/thread: file descriptor statuses are continuously checked and as soon as one of these has new buffered data a further call is issued to retrieve such data. It is intuitive that the polling strategy is the mechanism adopted by the OS Kernel, underneath, to check the status of the devices; having such a mechanism at application level, looks intuitively like a sort of heavyweight duplication of efforts.
NOTE Staged Event Driven Architectures (SEDA) [12] are able to combine the two levels of parallelism for a superior performance.
About Task Management
Three main techniques can be taken into consideration: Serial, Cooperative and Preemptive.
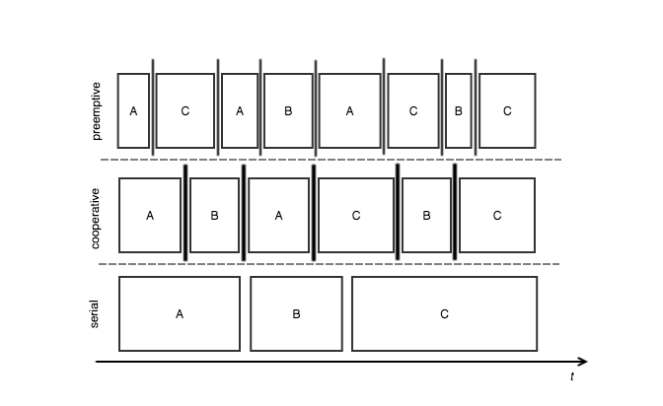
Serial. The simplest technique possible: first come, first served. Tasks are executed in sequence from their begin to their end. Clearly, there is no tasks interleaving.
Cooperative. Tasks are interleaved according to their own timeslices, it is a cooperative model of tasks execution because the tasks get allocated the CPU time according to specific execution time frames: each task can give up the CPU time to another task with same priority. As said, tasks are interleaved but the pattern is different if compared to a typical preemptive scheduling.
Preemptive. Tasks are not executed sequentially; they are interleaved by a signaling mechanism dictating when a task is able to carry on a new unit of work. It can be easily coupled with priority-based scheduling logic, since the signaling mechanism is able to interrupt running tasks. In such model, the scheduler has the full control of the interleaving strategy and for this reason, the achieved throughput may be sub-optimal.
The Linux kernel adopts a Completely Fair Scheduling (CFS) policy from version 2.6.3 [4]. The CFS scheduler maximizes the CPU time allocations adopting a Run Queue backed by a Red-back Tree: task poll is a O(1) operation, task enqueue is a O(log N) operation where N is the actual number of tasks. Such scheduler uses prioritized preemption: with the signaling mechanism in place, the Kernel is able to stop running tasks as soon as high priority tasks enter the running queue and fairness is met.
Task Vs Stack Management
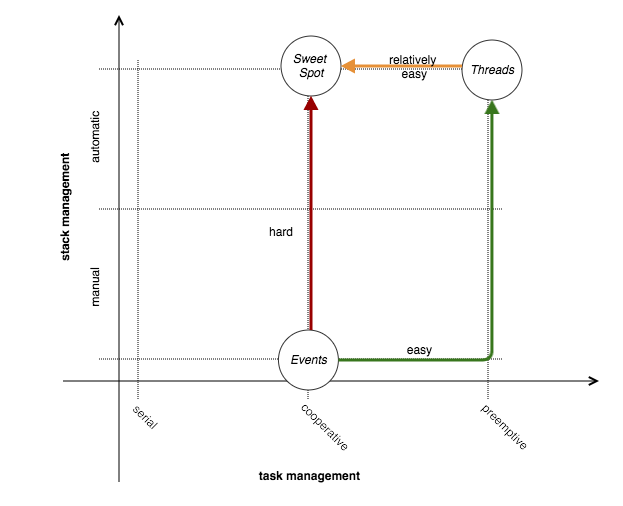
The call stack is a fundamental concept in programming, compilers adopt this data structure to preserve the processing context jumping in and out a/from subroutine calls. On the other hand, the tasks are an intrinsic unit of work for any OS, in fact even the processes are treated as many tasks to be scheduled on the CPU units by the Kernel Task Scheduler.
As clear, stacks for processes or threads are managed by the Kernel which takes care to switch the context by swapping in and out such stacks plus a few values of CPU registers, and thread-based concurrency takes benefit from this. With event-driven programming the concurrency is clearly targeted using one poller thread and benefiting from the parallelism of the IO devices: everything happens in the application, and so the processing stack for each class of events should be managed explicitly by applicative code.
Event-driven design implements a form of cooperative task scheduling: specific handler processing is the unit of work, and the turnover between the handlers implements the scheduling flow. On the other hand, thread-based design implements a form of preemptive task scheduling, in particular such scheduling is completely coupled to the OS Kernel scheduling.
In [5] the two models are analyzed with the aim to find the sweet spot between the two approaches: using the right mix of thread-based concurrency meanwhile dealing with non-blocking IO, a concept revamped by Matt Welsh with his SEDA [12]. The same work [5] highlights the intrinsic complexity and scalability limits of the pure event-based programming for dealing with non-blocking IO, for this reason in the above picture the path from ‘Events’ to ‘Sweet Spot’ is a hard one; much better to target the ‘Sweet Spot’ moving from the ‘Threads’.
Events intrinsic complexity
It is possible to understand that with events three fundamental problems raises up: Inversion of Control, Multi-core processors, and Listener life cycles [9].
Inversion of Control
Stack ripping phenomena [5]: stack reconstructed on the Heap. Callbacks are ideal for imperative programming languages which do not support/provide closures and so asynchronous callbacks represent the design pattern for event-based IO: callbacks are registered and invoked whenever an event of interest bubbles up. Callbacks suffer of the stack ripping problem which consists in the need to have the processing stack saved off-stack: as soon as a callback function is invoked to continue an IO operation, the context needs to be re-activated in order to consistently resume any previous operations. As clear, the context has to be saved off-stack because the callback function itself, as it is, gets allocated on the stack with its actual parameters: the invocation is stateless, on the stack goes the actual needed amount of data which normally corresponds to the actual input parameter values. The context needs to be saved on the heap and passed as input argument to the callback. This model is critically complex and unnatural: stack unrolling should be able to give back any context for the current computation which is not the case of callbacks for their nature of unrelated in space and time handling routines. The all point is in the sequential nature of operations which are split in successive asynchronous sub-operations by an event-based approach.
NOTE Closures mitigate the stack ripping problem but, as intuitive, not completely in complex scenarios.
Multi-core processing
Handlers in an event-loop should run sequentially to avoid corruption of the global state. Introducing locking with events would be outrageously complex to deal with.
Listener life cycles
Handlers live until registered. If an unregistration does not happen whenever the event cannot occur anymore, the handler lives forever without any sense to exist: it is a leak, just like it happens with memory management.
Threads intrinsic simplicity
As evident, the thread model has intrinsic simplicity from an engineering perspective. Let’s go through a few basic points.
Sequential Programming
Threads are sequential units of execution, by definition. Instructions are executed one after another among passivation and re-activations: any algorithm is written as thought.
Automatic Context Switch
Signaling at OS level handles the lightweight and cost inexpensive context switches.
Compiler and OS Support
The sequential memory model can be optimized by the compiler. On the other hand, the OS does the entire job underneath dealing with these lightweight processes and their resources allocation.
Native POSIX Linux Threads
LinuxThreads library historically had design pitfalls and compliance problems with the POSIX standard. The library was basically creating threads by cloning the father process into a new runnable process; from here the concrete issues with non-scalable signaling, heavyweight context switches as well as PID management. A task force composed by IBM and Red Hat engineers worked to solve the said problems and release a high-performance POSIX-compliant version of the thread library. From version 2.6 (late 2003) of the Linux Kernel, the NPTL library was integrated bringing to the Kernel a superior scalability in managing threads: system calls like the clone() were optimized, system calls like tkill() to specifically signal threads were introduced, thread ID was introduced as mechanism to deal with lightweight process identifier and condition-based locking primitives like futex() were introduced. Among the other things, the Linux Kernel for the same versions got substantial improvements for the process scheduling: a new constant-time scheduler was introduced to ease the NPTL integration, taking benefit of the superior level of scalability brought by the said system calls.
All the discussed improvements brought an optimized and lightweight context switch between now properly-said threads which share the memory, as well as all the other handlers. NPTL pushed the Linux Kernel towards an almost 0-cost thread management, from this the superior performances for applications like network servers heavily using threads.
Threads and Blocking IO
One would say, old design principles which make sense again. With the introduction of NPTL the results of Brewer make sense even in the general case, so the Linux OS. Paul Tyma in [11] demonstrates a clear performance gap of non-blocking IO when compared with blocking IO and multithreading: blocking IO is benchmarked 25% faster on average, offering a 25% higher throughput as showed in the below picture (credits to P. Tyma too).
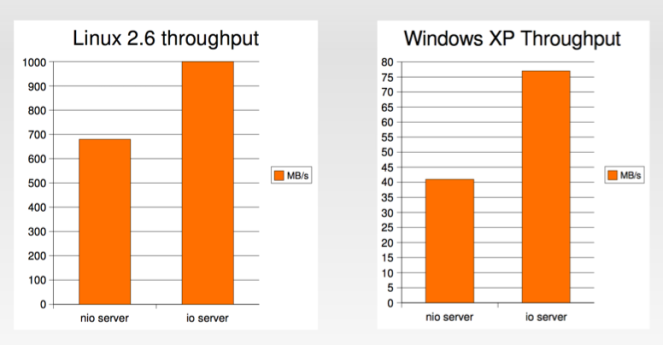
The rationale behind such performance resides in the overhead of events handling: rebuilding the stack, dealing with it and accommodating diversity are factors that at application level hit hardly the performance. This is quite evident if one thinks about the basic number of system calls needed to just retrieve the data from the File Descriptors (FDs) (periodic polling on the list of FDs, and systematic retrieval when new data is available); and, normally, applications are not a “comparable runtime” if on the other hand OS Kernels are used for doing the same things.
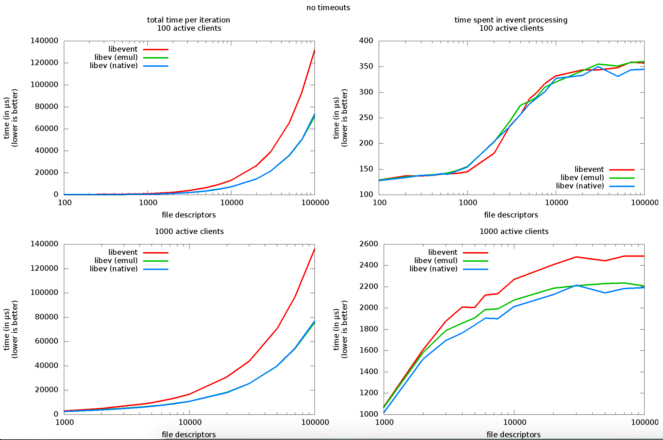
An interesting benchmark of libev (one of the best NIO library for C/C++ development) [13] highlights the relevant overhead introduced by the library to deal with i. sockets, ii. event watchers and iii. active clients: from 1000 FDs, and 100 active clients, the events processing overhead is very relevant (hundreds of microseconds), and between 1000 and 10000 such overhead almost doubles hitting hardly the scalability characteristics.
Looking back at the initial result proposed in [9] depicting a thread-based server over performing an event-based one, and having navigated a bunch of interesting concepts and technologies, meanwhile having spotted critical problems with event-based programming, now everything should make sense and clearly it is legitimate to say that: for ultra-scalable network servers, the Sweet Spot should be reached adopting such a complex SEDA architecture, but for relative superior performances the thread-based model should be enough.
Conclusion
In this journey a few interesting things came up: i. events are a bad idea with modern hardware architectures if the goal is OS-driven scalability, and ii. threads cost almost zero from an OS perspective. The referenced papers and links helped in reinforcing a few concepts, often sources of misconceptions.
As takeaway, and as a sum up of the narrative exploded till now, it is possible to say that: event-based concurrency is hard to i. program, ii. test and iii. track the overall control flow, moreover it is an unnatural way to deal with the stack (see Stack Ripping [5]). At this point, one would argue that thread-based concurrency is hard to i. program, ii. test and iii. track the overall control flow, and this is a fair statement; clearly, if compared to event-based concurrency, the thread-based approach is much simpler and the reason why resides in the OS-driven policies which do not have to be replicated at application level (far less applicative overhead).
Moreover, as intuitive, thread-based concurrency has a natural fit with modern multicore hardware architectures: just a commodity server with 48 vCPUs is huge waste if, by design, a few OS-level threads are used. Would you agree?
References
[1] On the duality of operating system structures, http://cgi.di.uoa.gr/~mema/courses/mde518/papers/lauer78.pdf
[2] Threads Vs Event, Virginia Tech, http://courses.cs.vt.edu/cs5204/fall09-kafura/Presentations/Threads-VS-Events.pdf
[3] Threads Vs Events, http://berb.github.io/diploma-thesis/original/043_threadsevents.html
[4] Completely Fair Scheduler, Wikipedia, https://en.wikipedia.org/wiki/Completely_Fair_Scheduler
[5] Cooperative Task Management without manual Stack Management, Usenix, http://www.stanford.edu/class/cs240/readings/usenix2002-fibers.pdf
[6] List of Intel Microprocessors, Wikipedia, https://en.wikipedia.org/wiki/List_of_Intel_microprocessors
[7] Non-blocking Algorithms, Wikipedia, https://en.wikipedia.org/wiki/Non-blocking_algorithm
[8] Capriccio: Scalable Threads for Internet Services, Berkley University, http://capriccio.cs.berkeley.edu/pubs/capriccio-sosp-2003.pdf
[9] Why Events are a Bad Idea, Berkley University, http://capriccio.cs.berkeley.edu/pubs/threads-hotos-2003.pdf
[10] Native POSIX Linux Threads, Draft Design, https://www.akkadia.org/drepper/nptl-design.pdf
[11] Thousands of Threads and Blocking IO, https://www.mailinator.com/tymaPaulMultithreaded.pdf
[12] Staged Event Driven Architecture for well-conditioned Internet Services, Stanford University, http://www.cs.cornell.edu/courses/cs614/2003sp/papers/Wel01.pdf
[13] Libev Benchmark, http://libev.schmorp.de/bench.html
[14] Why Threads are a Bad Idea, Stanford University, https://web.stanford.edu/~ouster/cgi-bin/papers/threads.pdf
[15] CAP Theorem, Wikipedia, https://en.wikipedia.org/wiki/CAP_theorem
[16] LMAX Disruptor, https://lmax-exchange.github.io/disruptor/
[17] Azul Lock-free Hashtable, http://www.azulsystems.com/events/javaone_2007/2007_LockFreeHash.pdf
[18] LMAX Disruptor Performance Results, https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results

3 thoughts on “Scaling to Thousands of Threads”